Flink モニタリング
Flink(英語) プラグインを使用すると、Apache Flink(英語) ジョブを監視して送信できます。
典型的なワークフロー:
Apache Flink ダッシュボードを反映した専用ツールウィンドウを使用して Flink ジョブを監視する
Flink サーバーに接続する
ビッグデータツールウィンドウで
 をクリックし、Flink を選択します。
をクリックし、Flink を選択します。開いたビッグデータツールダイアログで、接続パラメーターを指定します。

名前 : 他の接続と区別するための接続の名前。
URL : ApacheFlink ダッシュボードの URL を指定します。
オプションで、次を設定できます。
プロジェクトごと: これらの接続設定を現在のプロジェクトでのみ有効にする場合に選択します。この接続を他のプロジェクトで表示する場合は、選択を解除します。
接続を使用可能にする : この接続を無効にする場合は選択を解除します。デフォルトでは、新しく作成された接続は有効になっています。
トンネリングを有効にする : リモートホストへの SSH トンネルを作成します。ターゲットサーバーがプライベートネットワーク内にあるが、ネットワーク内のホストへの SSH 接続が利用可能な場合に役立ちます。
チェックボックスを選択し、SSH 接続の構成を指定します(... をクリックして新しい SSH 構成を作成します)。
HTTP 基本認証を使用可能にする : 指定されたユーザー名とパスワードを使用した HTTP 認証との接続。
プロキシ : IDE プロキシ設定を使用するか、カスタムプロキシ設定を指定するかを選択します。
設定を入力したら、接続のテストをクリックして、すべての構成パラメーターが正しいことを確認します。次に OK をクリックします。
Flink サーバーへの接続を確立すると、Apache Flink ダッシュボードを反映した Flink ツールウィンドウが表示されます。
ジョブ、その構成、例外、チェックポイントをプレビューします。フィルターフィールドを使用してジョブを名前でフィルタリングするか、![]() をクリックしてステータスでフィルタリングします。実行中のジョブがある場合は、
をクリックしてステータスでフィルタリングします。実行中のジョブがある場合は、![]() をクリックして終了できます。
をクリックして終了できます。

タスクを実行するノードを表示し、それらのログ、stdout、スレッドダンプを表示してダウンロードします。

Job Manager を表示し、ログと stdout を表示してダウンロードします。

アップロードされた JAR ファイルを表示し、名前またはエントリクラスでフィルタリングして、新しい Flink ジョブを送信します。

新しいジョブを送信
Flink ツールウィンドウで、新しいジョブを送信タブを開きます。
アプリケーションの JAR ファイルがまだ Flink クラスターにアップロードされていない場合は、
 をクリックして新しいファイルを選択します。
をクリックして新しいファイルを選択します。アップロードされたファイルを選択し、
 をクリックします。
をクリックします。開いた JAR ファイルを提出するウィンドウで、次のパラメーターを設定します。
復元されていない状態を許可する : 新しいプログラムにマップできないセーブポイントの状態のスキップを許可します (allowNonRestoredState(英語) オプションと同等)。
エントリクラス : プログラムエントリクラスに入る。
プログラム引数 : プログラムの引数を入力します。
並列処理 : タスクの並列インスタンスの数を入力します。必要なタスクインスタンスが 1 つだけの場合は、空白のままにします。
セーブポイントパス : ジョブの実行状態イメージ (savepoint(英語)) のパスを入力します。

ジョブを送信したら、ジョブタブでそのステータス、開始時刻、その他のパラメーターをプレビューできます。
関連ページ:
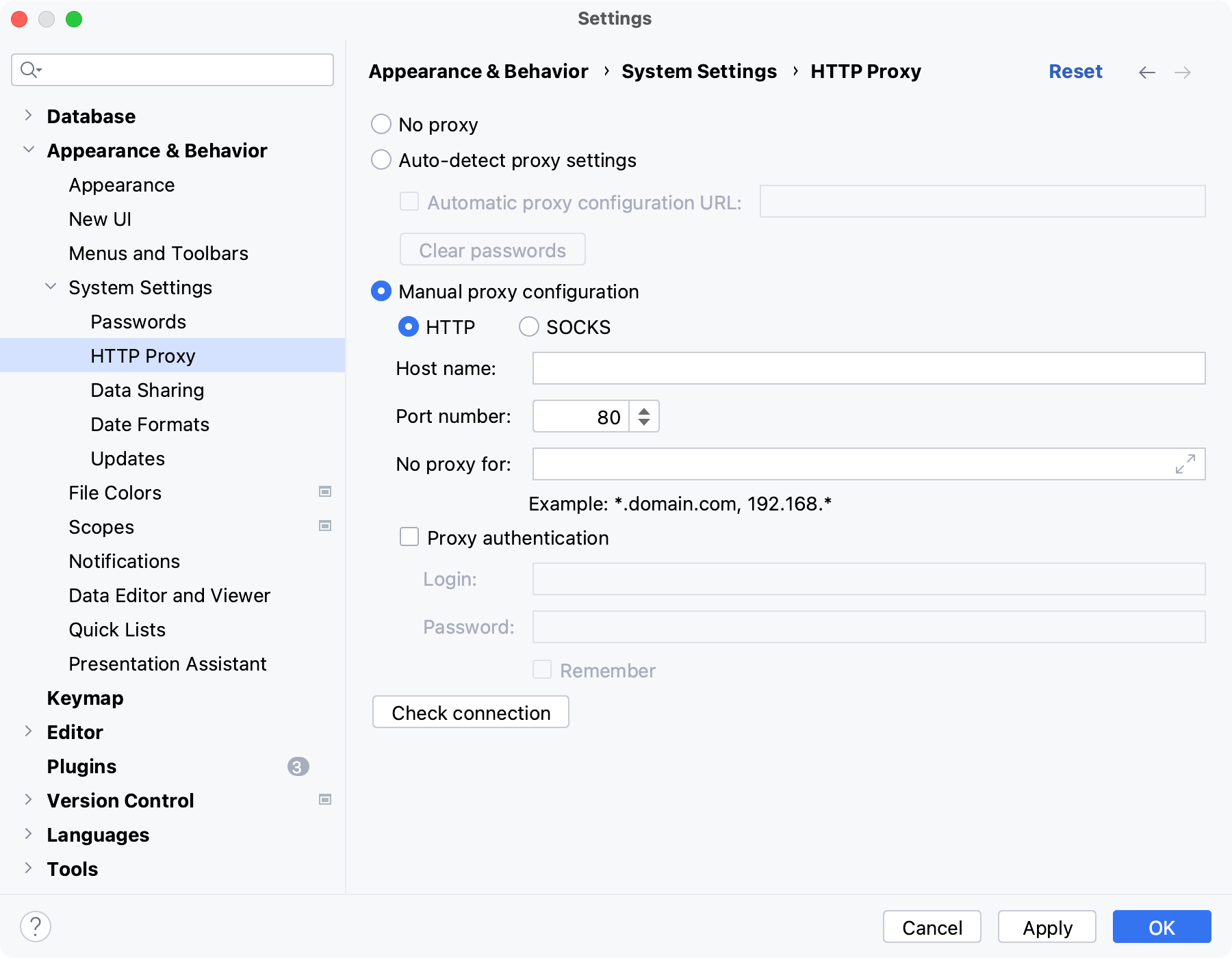
HTTP プロキシ
DataGrip がインターネットにアクセスするときにトラフィックを通過させたい場合は、HTTP または SOCKS プロキシサーバーの設定を指定します。HTTP プロキシは、HTTP 接続と HTTPS 接続の両方で機能します。これらの設定は、JDBC ドライバーのダウンロード、プラグインのダウンロード、ライセンスの有効性の確認、インスタンス間での IDE 設定の同期、および IDE 自体のその他のタスクを実行するために DataGrip が確立する接続に影響します。プロキシなしプロキシなしで直...

AWS Glue
DataGrip を使用すると、AWS Glue プラットフォームを監視できます。典型的なワークフロー:AWS Glue サーバーへの接続を確立する、エディターでストレージをプレビュー、専用のツールウィンドウでデータベースとパーティションをプレビューする、AWS Glue サーバーに接続するビッグデータツールウィンドウで、をクリックし、AWS Glue を選択します。開いたビッグデータツールダイアログで、接続パラメーターを指定します。名前: 他の接続と区別するための接続の名前。領域: バケットを取...
Zeppelin ノートブック
Zeppelin プラグインの開発は現在中断されています。問題が発生した場合は、問題を送信し、プラグインと IDE のバージョンをお知らせください。Zeppelin プラグインの詳細については、DataGrip ドキュメントのバージョン 2023.3 を参照してください。Flink モニタリング Kerberos